Training-to-serving pattern
Usecase
- モデルの学習完了後、自動リリースしたいとき
- リリースしたモデルを自動で本番サービスに組み込みたいとき
- モデルを安定して学習することができるとき
- モデルの更新が頻繁に発生するとき
Architecture
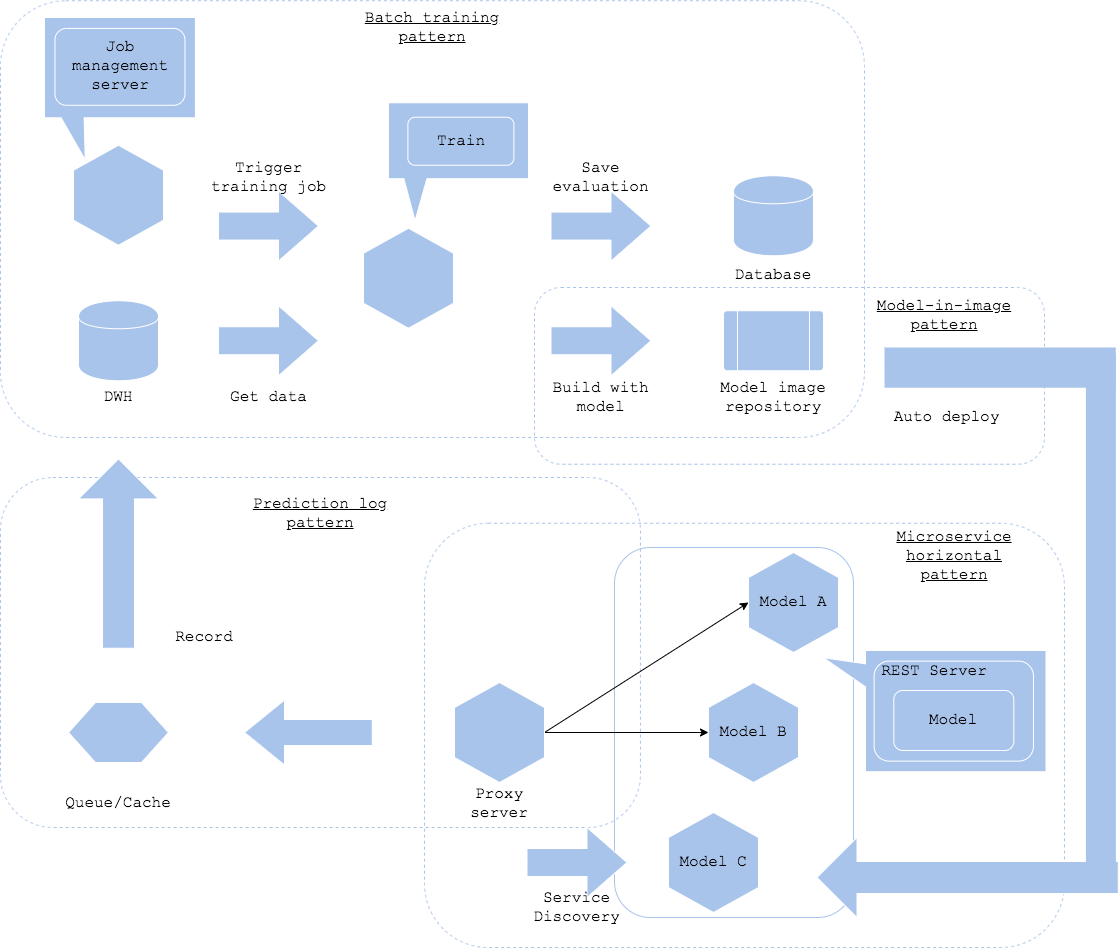
学習パイプラインと推論器のリリースを同一のワークフローで連続して実行する場合、学習-推論パターンを選択することができます。本パターンでは学習パイプラインを実行し、モデルをビルド、推論器をビルドした後に、自動的に本番サービスにリリースして推論に組み込むことを目的としています。モデルの更新が頻繁に発生し、マニュアルでの評価が不可能な場合、本パターンを選択することが可能です。
学習パイプラインはバッチ学習パターンやパイプライン学習パターンを選択することが可能です。パラメータ&アーキテクチャ探索パターンはアウトプットが安定するとは限らないため、本パターンと組み合わせるには不向きな場合が多いです。
学習されたモデルはモデル・ロード・パターンまたはモデル・イン・イメージ・パターンでリリースします。推論器のベースとなるサーバ・イメージが共有可能であればモデル・ロード・パターンが有効ですが、サーバ・イメージとモデルを1:1対応で管理したい場合はモデル・イン・イメージ・パターンが有効です。
推論パターンは並列マイクロサービス・パターンが良いでしょう。新しい推論器を他の推論器と並列に自動デプロイしていき、プロキシでサービス・ディスカバリを組み込むことでリリースされた推論器を自動で発見、接続するというワークフローです。
サービス運営の観点で、推論ログパターンおよび推論監視パターンは必須でしょう。
学習-推論パターンでは学習後に自動的にモデルをリリースし、本番サービスに組み込むことが可能です。注意点として、モデルの学習と評価結果が大きく上下しないことや、学習パイプラインが安定稼働することが必要になります。モデル学習が不安定な場合、本番サービスに適さないモデルがリリースされるリスクとなります。学習パイプラインが不安定な場合、そもそも学習やリリースが正常動作しないことが懸念点です。また、リリースしたすべてのモデルを常に稼働させ続ける必要があるか、検討が必要です。何らかの理由でモデルが不要になった場合(たとえば学習に使用したデータが古く、推論の精度が下がった場合)、当該推論器を本番サービスから除外する必要があります。可能であれば、一定期間が経過したら自動で推論器を除外する運用であれば、容易に開発することが可能ですが、サービスの目的次第では有用な推論器が削除される懸念があります。他方でモデルの評価等を基準に除外を判定する場合、評価パイプラインを開発し運用する必要がありますが、有用な推論器を削除するリスクを軽減できます。
Diagram
Pros
- 学習後のモデルを自動で本番サービスにリリースすることが可能
- 頻繁にモデルをリリースすることが可能
Cons
- 学習パイプライン、自動リリース、サービス・ディスカバリ等を開発する必要がある
- モデルの学習結果が不安定な場合は本パターンは不向き
Needs consideration
- モデル学習の安定性、学習パイプラインと自動リリースの安定性とサービスレベル
- サービス・ディスカバリおよび不要な推論器の削除ポリシー