Batch training pattern
Usecase
- 定期バッチでモデル学習を実行したいとき
Architecture
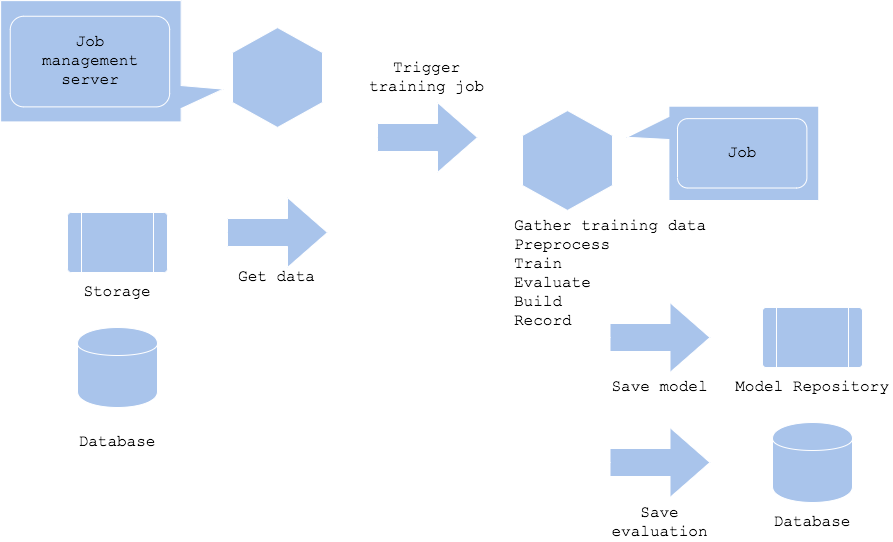
機械学習のモデルを定期的に更新したい場合、バッチ学習パターンが有効です。学習をジョブとして定義し、ジョブ管理サーバにジョブの起動条件(日時、データ量、利用量等)を定義してジョブを実行することができます。ジョブ管理は簡単に構成するならLinuxのcronが使えますし、各種クラウドで提供されている定期実行サービスを活用することも可能です。SIerが提供するジョブ管理サーバも良いでしょう。
バッチ学習パターンはオフラインでモデル学習する最も典型的なアーキテクチャーになります。バッチのジョブフローには以下が含まれます。
- DWHからデータ収集(データの異常診断含む)
- データの前処理
- 学習
- 評価
- モデルおよび推論器のビルド
- モデル、推論器、評価の記録
各フローでエラーが発生した際の対処はバッチと推論器のサービスレベル次第で検討します。
推論モデルを常に最新に保つ必要がある場合(サービスレベルが高い)、エラー時にはリトライするか、運用者に通報する必要があります。常に最新である必要がなければ、エラー通報だけしておいて、翌日等に手動で実行するものでも良いでしょう。
エラーが発生した場合は、エラー箇所を記録し、エラーログから復旧手段やトラブルシューティングを実施できるようにしておく必要があります。上記ジョブフローのうち、1.では外部の入力データが不良である可能性があるため、データの異常診断や異常値検出等を行うことが妥当です(Int値にChar値が入っている、0~1の範囲に収まる筈の値に10が含まれている等々)。異常データが含まれていたためにジョブが停止した場合、自動リトライで対応することは不可能なため、事前に異常値を除外する実装にするか、マニュアルで除外する必要があります。
他方で2.~4.においては、モデルの性能(評価値)が必要なサービスレベルを満たさない可能性も考えられます。この場合、前処理方法やハイパーパラメータが現状のデータに適合していない可能性が考えられるため、データ分析とモデルのチューニングが必要になります。
5.と6.はビルドエラーや記録エラー等、システム障害に起因する場合が考えられます。ビルドや記録に使用しているシステム(サーバ、ストレージ、データベース、ネットワーク等)の障害レポートを確認する必要があります。
Diagram
Pros
- 定期的にモデルを学習し更新することが可能。
Cons
- ジョブのエラー時対応を検討しておく必要があり、完全自動運用は困難な場合が多い。
Needs consideration
- ジョブ管理サーバの選定。
- エラー時の対応方法。