Training code in serving pattern
Case
- 학습, 실험, 평가에만 사용되야 하는 코드가 서빙 코드에 들어간 경우.
- 학습, 실험, 평가를 위한 환경과 구성이 서빙에도 들어간 경우.
Situation
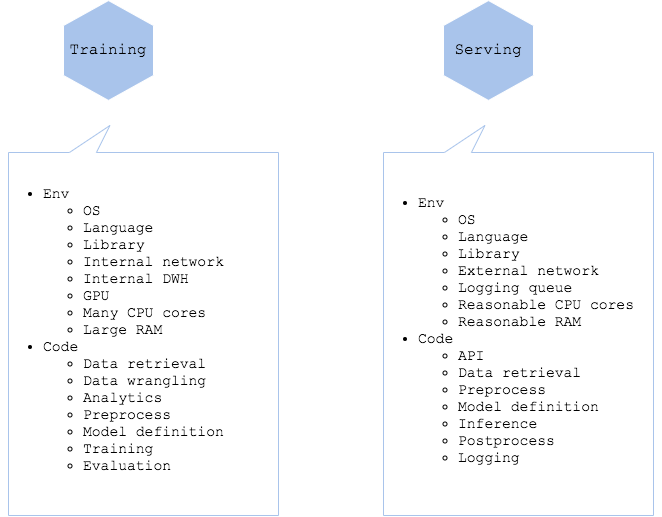
학습, 실험, 평가 등 머신러닝 개발을 위한 코드와 로직은 대부분 실제 운영 서비스용과는 다릅니다. 예를 들어 코드 내에서 사용하는 라이브러리 의존성이 다를 수 있습니다. 또, 데이터 분산, 배치 학습, 파라미터 튜닝 등은 학습 단계에서 사용되지만 실제 서비스에서는 이러한 구현을 거의 하지 않습니다. 이러한 학습과 서빙의 다른 점이 머신러닝을 실제 운영 시스템에 적용하기 어려운 이유 중 하나입니다. 업데이트 제한, 장애 분리, 코드 가동성 등을 위하여 실제 시스템에는 불필요한 코드를 포함하지 않도록 해야 합니다. 특히, 학습 코드는 서빙 환경에 포함하지 않는 것이 좋습니다.
CPU, GPU, RAM, 네트워크 및 스토리지와 같은 학습을 위한 리소스들은 서빙용과 따로 분리되어야 합니다. 웹 서비스의 경우, 학습을 위한 네트워크와 스토리지는 내부로 제한하고 서빙을 위한 것만 외부로 공게 해야 합니다. 또, 딥러닝의 경우, 학습용으로 GPU, 서빙용은 CPU를 사용하는 방법 혹은 학습용 GPU와 예측용 GPU를 따로 사용하는 방법이 일반적입니다. 이와 같은 이유들로, 학습 환경에서 사용하는 리소스 설정치들이 서비스 환경에서는 불필요 혹은 잘못된 설정들 일 수도 있습니다. 설정들을 포함하되 사용하지 않는 방법도 있으나 이럴 경우 장애로 이어질 수 있으므로 주의가 필요합니다.
하지만, 학습 단계의 퍼포먼스나, 지연시간, 정확성 등을 유지하기 위해서 코드나 설정을 동일하게 구성해야 할 때도 있습니다. 여기서 중요한 것은 무엇을 공통 표준화할 것이고 어떤 것은 분리하여 만들 것인가를 구분하는 것입니다.
- 학습 및 서비스 환경의 표준화해야 하는 부분:
- OS, 언어, 라이브러리 버전들
- 전처리, 예측, 후처리 등에 사용되는 코드와 로직
- 분리되어야 하는 부분:
- 학습에 이용되는 코드와 로직
- 학습을 위한 라이브러리나 리소스들(학습용 GPU, 대용량 CPU나 RAM, 내부 네트워크와 내부 데이터 웨어하우스)과의 의존성
Diagram
Pros
- 배치 예측에서는 학습과 서빙을 동일한 환경에서 실행시킬 수도 있습니다.
Cons
- 학습용과 서빙용 코드와 설정들을 분리하는 수고가 필요합니다.
Work around
- 코드와 설정들을 분리하는 것이 당장은 어려울 수는 있으나, 장기적으로 비용과 보안, 기밀정보(네트워크와 데이터 액세스)보호 측면으로는 반드시 분리하는 것이 좋습니다.