Too many pipes pattern
Case
- 학습 파이프라인이 너무 다양하고 복잡한 경우.
- 데이터 소스가 너무 많고 가져오는 방법이 적절히 추상화되어있지 않은 경우.
Situation
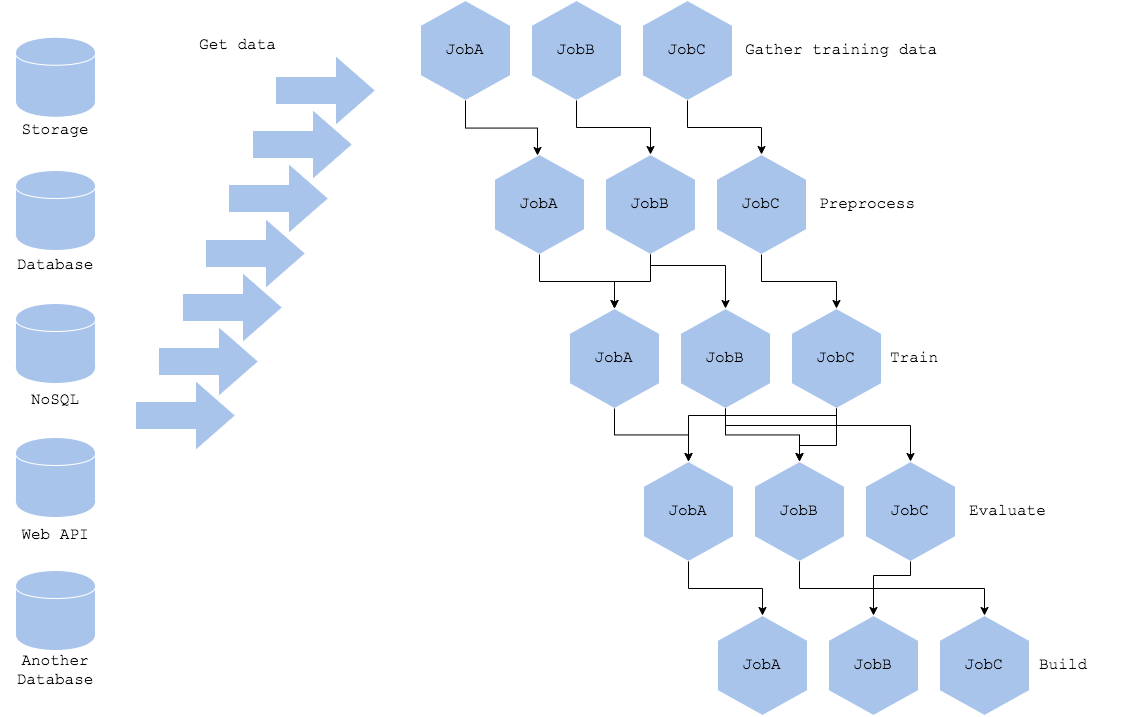
머신러닝의 학습 파이프라인은 학습뿐만 아니라 모델 튜닝, 실험, 평가에도 사용할 수 있습니다. 다양한 파라미터 튜닝과 실험을 병행하기 위해서는 파이프라인을 다양하게 사용될 수 있도록 만들어야 합니다. 만약 파이프라인 작업 간의 의존관계가 있다면 더욱 복잡해질 수 있습니다. 파이프라인의 에러 해결 및 트러블 슈팅과 같은 운영을 위해 SRE(Site Reliability Engineering)가 필요할 수도 있습니다. 따라서 학습 플랫폼을 내부 시스템으로 만들 때는, 최대한 단순화하여 장애를 격리하고 재사용성을 높이는 것이 중요합니다.
파이프라인을 복잡하게 만드는 또 다른 이유는 데이터 소스와 액세스 방법의 다양함입니다. 데이터가 여러 데이터 웨어하우스(RDB, NoSQL, NAS, 웹 API, 클라우드 스토리지, Hadoop 등)에 저장되면 각 데이터 웨어하우스에 대한 액세스, 인증 및 권한 부여를 정의하는 작업이 늘어나며 복잡해질 수 있습니다. 각 데이터 액세스 객체를 관리할 수 있는 추상화된 라이브러리를 사용하는 것을 권장하나, 여러 웨어하우스에 분산된 데이터는 데이터 엔지니어에게 시련과 고통을 줄 수 있습니다. 그러므로 적절하게 데이터 웨어하우스를 선택하고 정리하는 것이 중요합니다.
Diagram
Pros
- 복잡한 파이프라인을 통해 다양한 작업들을 실행할 수 있습니다.
Cons
- 운영하기 어려울 수 있습니다.
Work around
- 파이프라인을 위한 의존성 관리를 합니다.
- 항상 데이터가 정리되어야 합니다.