Too many pipes pattern
Case
- Too many routes in one training pipeline in complex state.
- Many data sources and access objects with less common abstract method.
Situation
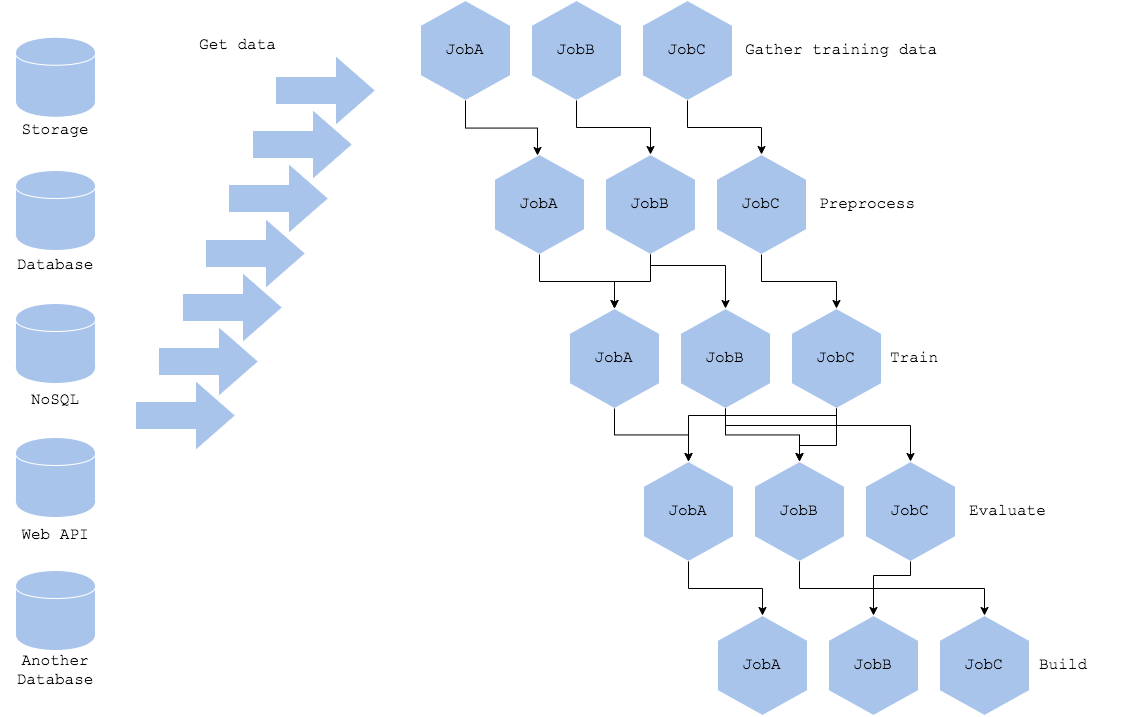
A machine learning’s training pipeline will not only do training, but also model tuning, experiment and evaluation. If you want to have various parameter tunings and experiments parallelly, the pipeline will be not one-way straightforward. If you have dependencies among pipeline jobs, its complexity increases. To maintain the pipeline, you may need SRE for the training platform to deal with errors and troubleshooting. When you make the training platform as one of internal systems to be maintained, it is suggested to make the pipeline as simple as possible to isolate fault and increate usability.
Another reason that makes a pipeline complex is various data sources and access methods. If your data is stored in a number of DWH (RDB, NoSQL, NAS, Web API, cloud storage, Hadoop, multiregional, and so on), defining access, authentication and authorization to each of them will be a mess. It is recommended to use a common library to manage data access object, though spreading data to multiple warehouses will give a data engineer hard time and unhealthiness. It is always better to choose appropriate and limited number of DWH.
Diagram
Pros
- Able to run various jobs with complex pipelines.
Cons
- Difficult to maintain and understand.
Work around
- Good to have dependency management when defining pipeline.
- Always organize data