Serving template pattern
Usecase
- 同一入出力の推論器を大量に開発、リリースする場合
- 推論器のうち、モデル以外を共通化することができる場合
Architecture
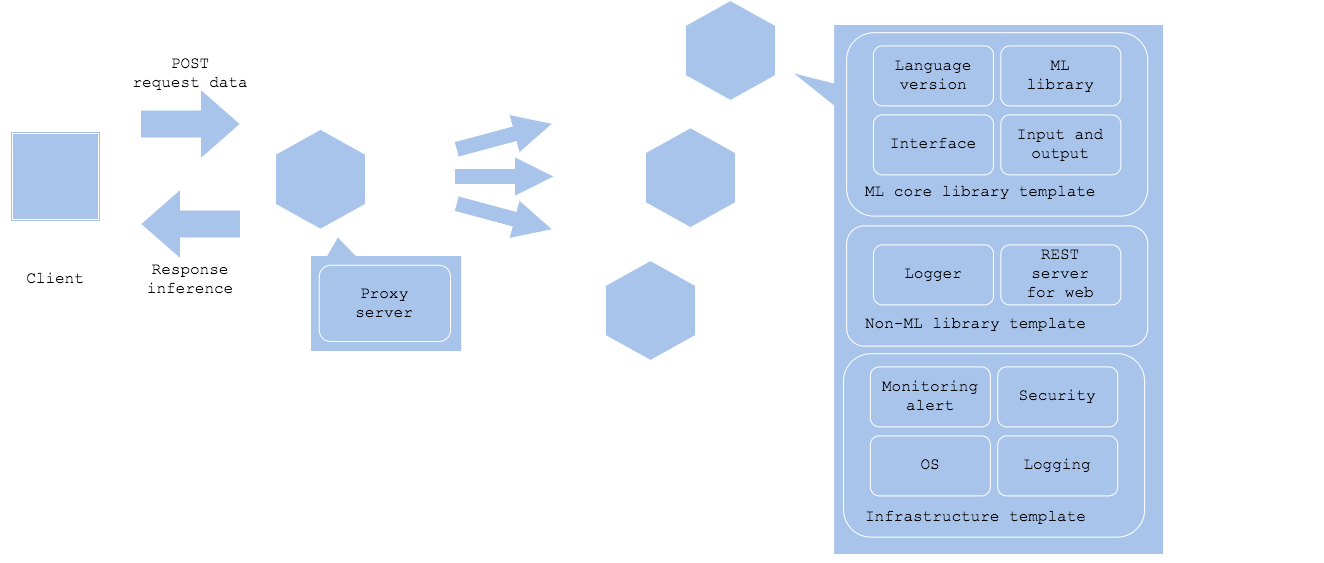
推論テンプレート・パターンは推論器のコードやインフラ構成、デプロイ方針を共通化し、再利用可能なテンプレートを用意するパターンです。推論器の方式を共通化することによって、推論器開発およびリリースを効率化すると同時に、システム理解やトラブルシューティングのノウハウを応用することが可能になります。機械学習モデルによる推論を大量に組み込んだシステムを開発する場合、入出力インターフェイスや推論モデルの呼び出し等が各推論器で異なる構成だと、各推論器の開発効率が下がります。すべての機械学習モデルが異なった入出力とライブラリ、OS、チップセットを使用する必要があるのであれば致し方ないですが、そうでない場合(例えばほとんどのモデルがPython3.xを使ってUbuntu18.0x上でx86_64アーキテクチャでNginxプロキシを使い、FastAPIによるRESTサーバとして稼働し、モデルはScikit-learnとKerasを使用して開発している場合)、共通の開発・推論テンプレートを用意することで、開発者の環境構築が不要になります。更には前処理と推論モデルの呼び出し方、出力を共通化できれば、モデルを組み込むだけで推論機を稼働させられるテンプレートを用意できます。
推論テンプレート・パターンでは共通化可能な部品を共通化し、再利用可能にします。理想的にはモデル固有の箇所をJSONやYAMLのパラメータで設定するだけで推論器をリリースできる状態ですが、そこまで共通化できなくても、前処理と推論モデル呼び出し以外のPythonコード(ライブラリバージョン含む)を共通化できれば、開発者のコーディング量が大きく削減されるはずです。加えてインフラレイヤーとして監視通報やログ収集、認証認可等を共通化することも可能です。全推論器を網羅するテンプレートを作ることが難しいとしても、社内でインフラのみ共通化し、チーム内では機械学習に関わらないミドルウェアとライブラリをテンプレート化し、そしてプロジェクトでは機械学習モデル以外を共通化するという方針にすることで、開発効率を向上させることも可能です。
推論テンプレート・パターンを利用する際の注意点は、テンプレートのバージョンアップが必要な場合、稼働中のサービスのアップデート方針です。テンプレートの更新では基本的に後方互換性を保った更新が必要です。後方互換性が保たれているのであれば、各サービスのサービスレベルに応じて推論器の入れ替えを行います。バッチサーバであればバッチ稼働中以外に更新可能ですし、RESTサーバ等のオンラインサービスであれば、オンラインABテスト・パターンで徐々に入れ替えていく方針が考えられます。ただし、後方互換性を保てないテンプレート更新が必要になる場合は注意が必要で、場合によっては全推論器のインテグレーション・テストを再実行する必要があります。
最後に、インフラ含めた機械学習モデル固有要件のテンプレート化レベルを以下に示します。
- インフラ(機械学習モデルに依らず共通化可能。ただし、モデルが特定のチップセットやランタイムが必要な場合はこの限りではない)
- OS
- ネットワーク
- 認証認可
- セキュリティ
- ログ収集
- 監視通報
- 非機械学習のミドルウェアやライブラリ(多くの場合機械学習モデルに依らず共通化可能)
- Webサーバやジョブ管理サーバ
- ロガーライブラリ
- RESTサーバライブラリやProtocol bufferとGRPC
- 機械学習モデルを稼働させるためのプログラミング言語やライブラリ(機械学習モデル固有になる場合あり)
- プログラミング言語のバージョン
- ライブラリのバージョン
- 入出力インターフェイス
- 入力データと出力データ
Diagram
Pros
- 開発効率を向上させることができる。
- 同一の運用方針で管理することができる。
- 品質の良いテンプレートを作ればバグが混入する可能性も削減可能。
Cons
- テンプレートを更新する際には注意が必要。
Needs consideration
- テンプレートの後方互換性維持およびアップデート方針。
- 後方互換性を保てない場合のインテグレーション・テスト方法。
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter4_serving_patterns/template_pattern