Preprocess-prediction pattern
Usecase
- 前処理と推論でライブラリやコードベース、リソース負荷が違うとき
- 前処理と推論を分割することで障害分離し、可用性を向上させたいとき
Architecture
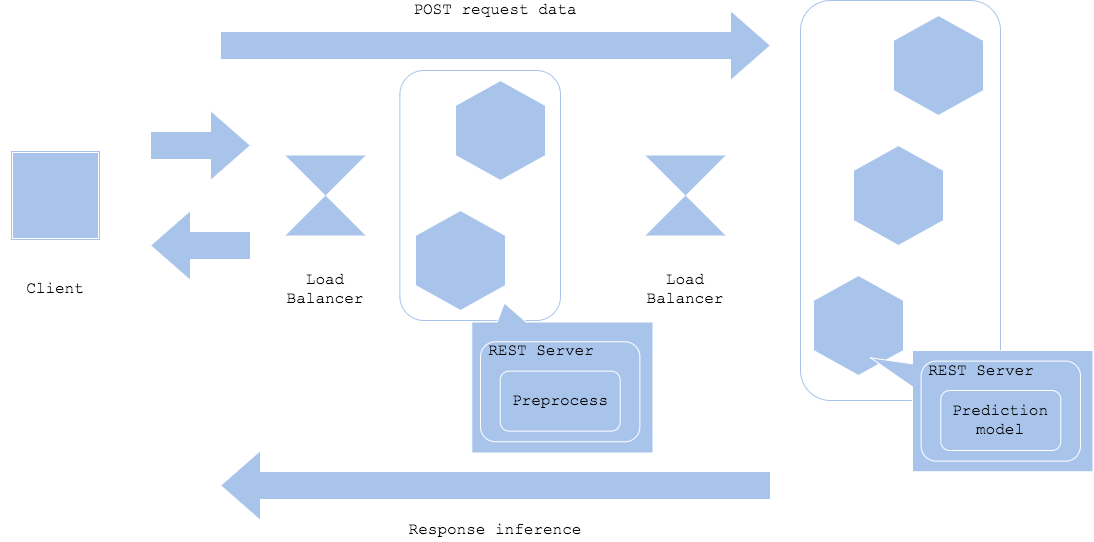
推論器の前処理と推論で必要なリソースが違うことがあります。前処理では数値の標準化や正規化、カテゴリのone-hot encoding、自然言語の形態素解析、画像のリサイズ、補完データの取得等が実行されます。推論では各機械学習ライブラリでモデルがビルド(バイナリ化)されており、データを入力すれば推論が得られる構成になっていることが多いです。前処理がPythonでスクリプトとして書かれている一方、ビルドされた機械学習モデルはバイナリ化されていることもあります(例:Tensorflow servingやONNX)。そのため、前処理と推論でサーバやコンテナを分割し、開発と運用を効率化することができます。
前処理器と推論器を分割するため、それぞれのリソース・チューニングや相互のネットワーク設計、バージョニングが必要になります。Webシングル・パターンよりも構成は複雑になりますが、前処理・推論パターンでは効率的なリソース活用や個別開発、障害分離が可能になります。特にディープ・ラーニングを推論器に使用するアーキテクチャでは、前処理・推論パターンになることが多いです。
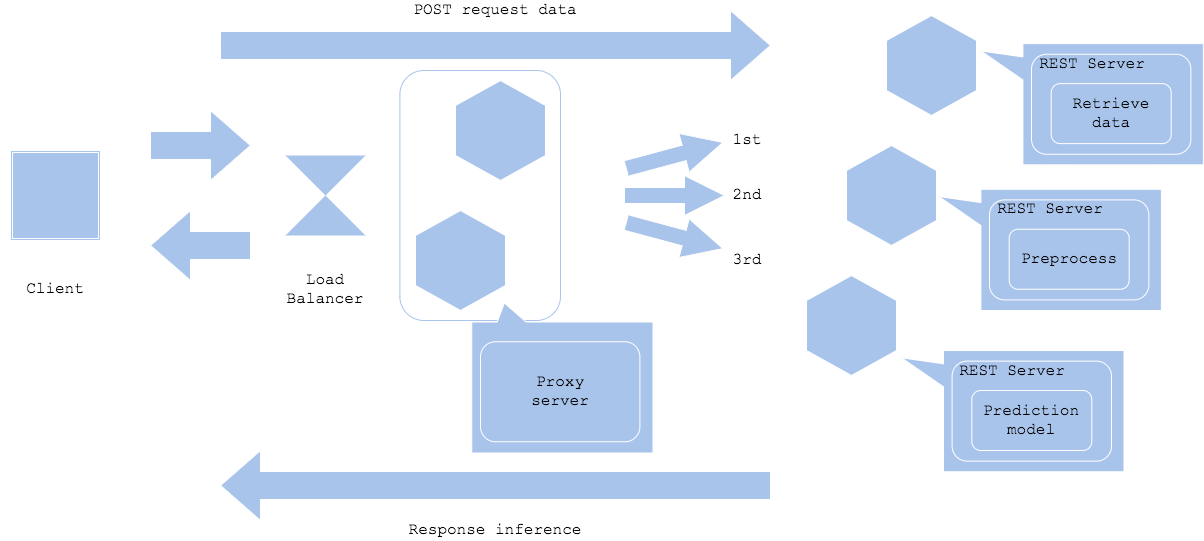
Diagram2のように前段にプロキシを配置して、前処理と推論をマイクロサービス化するパターンも可能です。その場合、プロキシを仲介させてデータ取得、前処理、推論を分割した構成になります。こうすることによって、データ取得サーバ、前処理サーバ、推論サーバを独立したライブラリやコードベース、リソースで開発することができます。ただしコンポーネントが増えるぶん、コードベースやバージョン管理、障害対応が難しくなります。
Diagram
Simple prep-pred pattern
Microservice prep-pred pattern
Pros
- 前処理と推論でサーバやコードベースを分割することで、リソース効率化や障害分離が可能。
- リソースの増減を柔軟に実装することができる。
- 使用するライブラリのバージョンを前処理と推論で独立して選択することが可能。
Cons
- 管理対象のサーバやネットワーク構成が複雑になるため、運用負荷増加。
- 前処理器・推論器間のネットワークがボトルネックになることがある。
Needs consideration
- 前処理モデルと推論モデルで独立して学習することはできないため、前処理と推論のパラメータを一致させる必要がある。
- 前処理モデルと推論モデルで独立して学習している場合、システムとしては障害にならないことが多いが、推論結果が想定外になることがある。
- 前処理器と推論器のリソースを個別にチューニングすることが必要。
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter4_serving_patterns/prep_pred_pattern