Prediction cache pattern
Usecase
- 동일한 데이터에 대한 예측 요청을 받고, 동일한 데이터를 식별할 수 있는 경우.
- 예측 결과가 자주 변경되지 않는 경우.
- 입력 데이터는 캐시로 검색할 수 있습니다.
- 예측과 오프로드를 가속화합니다.
Architecture
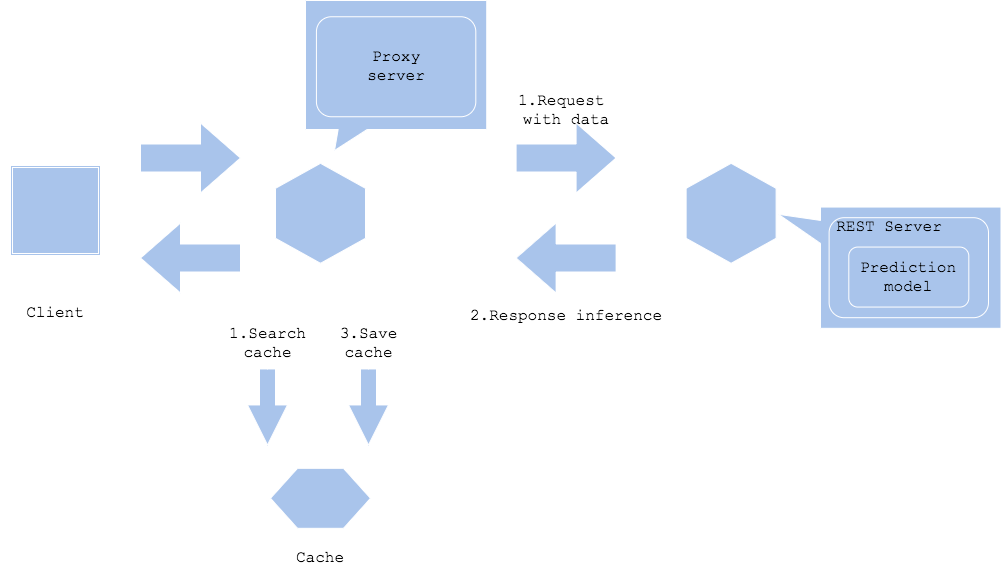
Prediction cache pattern은 예측 결과를 캐시에 저장해 나중에 반복되는 동일한 데이터에 대한 요청을 검색할 수 있습니다. 서비스가 동일한 데이터에 대해 요청을 받고, 동일 데이터를 식별할 수 있는 경우에 이 패턴이 이점을 가집니다.
예측 서버 또는 프록시는 입력 데이터를 캐시 key로 저정하고 키가 없는 경우 예측 결과를 value로 저장합니다. 캐시가 끝나면 캐시 검색과 예측이 병렬로 실행되며 예측이 완료되기를 기다리지 않고 캐시가 히트하면 값을 반환합니다. 예측 서버에 대한 부하를 줄여 예측에 걸리는 시간을 단축됩니다.
캐시할 데이터 양은 비용과 볼륨의 균형을 고려해야할 수 있습니다. 캐시 공간의 단가는 더 작은 스토리지나 데이터베이스보다 비싼 경향이 있으므로 캐시 삭제 정책을 만드는 것을 추천합니다.
예측 결과가 시간이 지나며 변하는 경우, 오래된 예측으로 응답하지 않도록 오래된 캐시를 지워야 합니다. 캐시 크기가 빠르게 증가할 정도로 서비스 로드가 높아지면, 캐시 삭제 정책을 구체적으로 설정하는 것이 중요합니다. 대부분 시간이 경과하거나 키의 요청 빈도에 따라 캐시가 지워집니다.
Diagram
Prediction cache
Pros
- 요청을 예측 서버로 오프로드 가능하고, 성능을 개선할 수 있습니다.
- 응답이 빠를 수 있습니다.
Cons
- 캐시 서버 비용.
- 캐시 정리 정책.
Needs consideration
- 입력 데이터로 고유하게 식별이 가능해야 합니다.
- 속도, 비용, 볼륨의 트레이드오프를 고려해야 합니다.
- 캐시 정리 정책이 필요합니다.
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter4_serving_patterns/prediction_cache_pattern