Multiple stage prediction pattern
Usecase
- To use ML prediction for interactive application.
- When you have lightweight prediction and heavy prediction for one purpose.
Architecture
The multiple stage prediction pattern is available when its workflow is to respond to its client in multiple stages. ML model in general tends to be lightweight for table and numerical data, while heavy for unstructured data, such as image and text. Some services require to have a quick response, with adding better prediction later to improve user experience. For web applications, it is important to take a balance of speed and accuracy, and especially for interactive applications, it is possible to consider a usecase where you first return a quick prediction, and then add the better ones in the next screen or downward. The pattern is effective to these interactive applications.
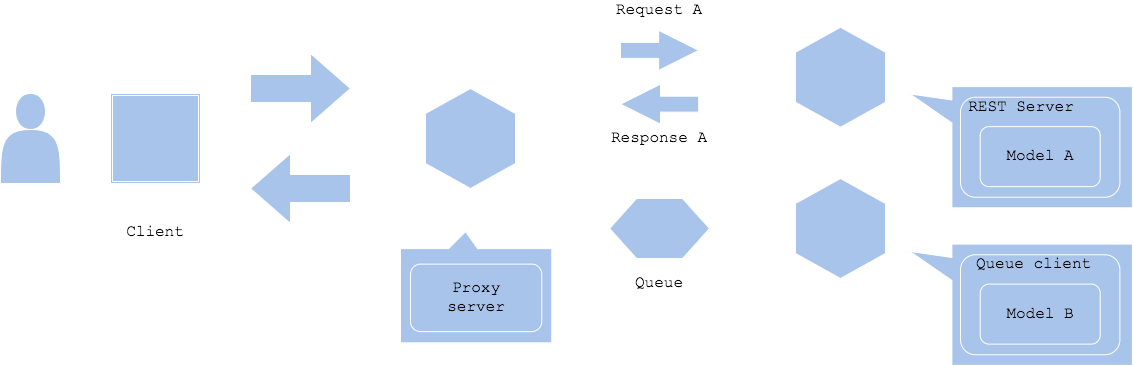
The pattern contains two prediction servers. One is to respond quick synchronously, and another one to predict later asynchronously. The first one is used to respond quickly with a fare accuracy using REST or GRPC interface. The latter will be slower, so asynchronous queue or messaging service is useful. The models to be in production depends on the requirement for the quality of prediction and speed to respond, though it might be separated with the data to be used, for instance numerical and categorical data for the synchronous prediction, and the image and text for the asynchronous, if the system uses multiple modality.
Diagram
Pros
- Respond quickly and then predict better.
Cons
- You need multiple services and interfaces.
Needs consideration
- Balance of speed, accuracy and user experience.
- How to provide the heavy predictions.