Batch pattern
Usecase
- If there is no need for real-time or near-real-time prediction.
- If predictions are expected on a bulk of data.
- If running predictions is schedulable; hourly, daily, weekly or monthly.
Architecture
If you don’t have to run the predictions real-time, you may choose the batch pattern to run the predictions with the desired interval. You can schedule a batch prediction to a bulk of data regularly, such as daily, and store the results. Of course it can be hourly or monthly depending on the usecase. This pattern requires job management server to trigger the batch job. The job management server will launch the job as per your defined rules. The prediction server will be deployed along with the launch of the batch job. If you are using a cloud service or Kubernetes, starting and deleting the server based on the job will enable you to reduce your costs drastically as the server need not be up 24X7.
Diagram
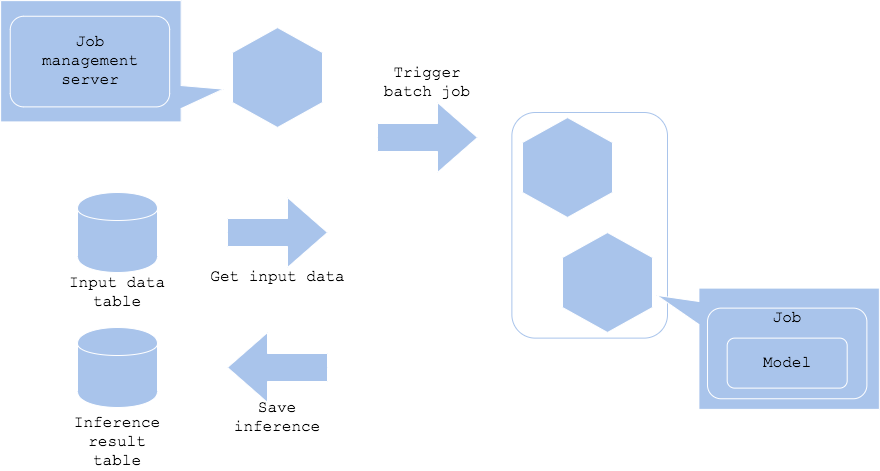
Pros
- You can manage server resources flexibly and in strict accordance with demand.
- You may rerun the job in case of error.
- There is no requirement for high availability in your server system
Cons
- You need a job management server.
Needs consideration
- You will need to consider the batch, or range, of dataset to predict in one job. If the dataset size for the defined interval is too large then it needs to be split and co-ordinated among several mini-jobs.
- If you have a certain time limitation to get the prediction results, you need to consider batch job schedule and server resources. If it is nightly batch, it is often case that you have to finish the job by next morning.
- Options to rerun the job in case of failure:
- Retry all: rerun the whole prediction of a batch. Used when a prediction or data has dependency on others.
- Partial retry: rerun on the failed dataset. Used when there is no dependency.
- No retry: run prediction on the failed dataset on the next batch. Used when there is no strict time limitation.
- If the batch timeframe is long, like once per month or once per year, it is suggested to monitor, or run temporarily, of the batch execution, for the model or system may be outdated.
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter4_serving_patterns/batch_pattern