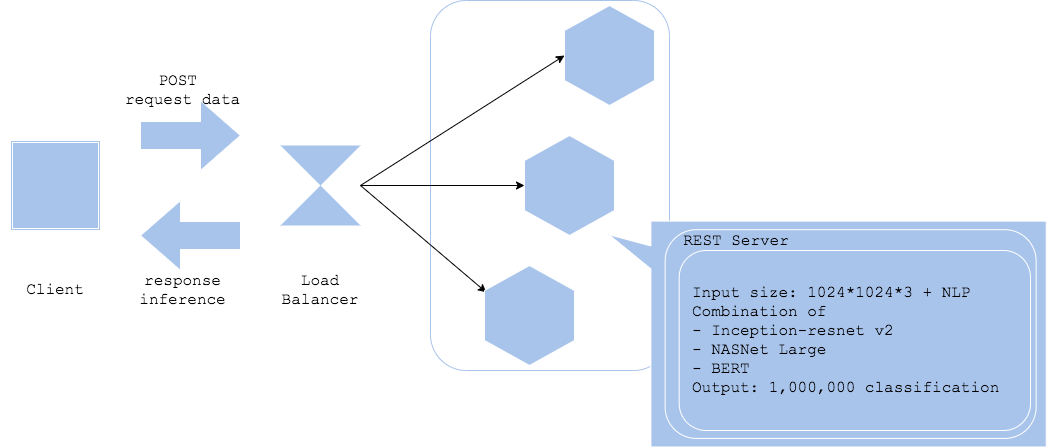
All-in-one pattern
Case
- When you are running multiple inference models in one server or one server group.
Situation
While there are many usecases you need to deploy multiple inference models for one product, it is recommended not to run them in one same server or a same server group. Running all the models in a monorithic environment may barely reduce server cost, though it will probably increase operational cost with difficulty of software development, troubleshooting and update.
A disadvantage for its model development in this situation is that you will get limitation in your library selection. Libraries and algorithms for machine learning have been changing rapidly. Developing a model aligned with another model development will become limitation in algorithm choice, that you may not be your best choice.
Once you get an incident in a monorithic architecture, you may need to trace all logs to find its root cause. Isolating fault in a system becomes difficult, as well as troubleshooting a machine learning model, such that prediction is invalid, requires tracing multiple logics, which will be increase in time to repair.
Updating system and model requires comparably long time as well. Depending on how you install your model, model in image patter or model load pattern, an update in the system will require an unnecessary update in a model. Frequency of system update and model update may not be synchronized, though those will be triggered simultaneously on a monorithic system, with increase in operational cost.
It is recommended to deploy in microservice architecture of one model per one server on running multiple models.
Diagram
Pros
- Barely reasonable cost.
Cons
- Increase in dev and ops cost.
Work around
- Develop in a single responsibility for a server and a model, in microservice.