Loading test pattern
Usecase
- 推論サーバのレスポンススピードを測りたいとき
- 推論サーバのアクセス負荷試験を行い、本番環境に必要なリソースを計測したいとき
Architecture
推論サーバのレスポンススピードや同時アクセス可能数はサービスの可用性に直結する重要な数値です。どんなに良い機械学習モデルを用意したとしても、1レスポンスに1分かかったり、1サーバが1リクエストしか受け付けられないという場合、サービスとして成立しません。もちろん大規模なリソースや推論用GPUを用意すれば可用性を担保することができるかもしれませんが、ビジネスとして成り立たない可能性もあります。
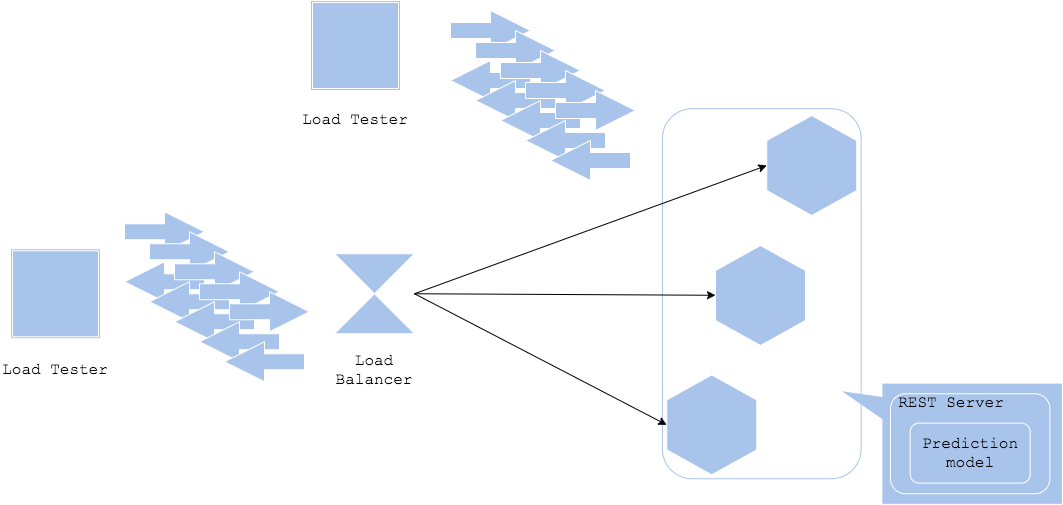
負荷試験パターンは、従来のWebサービスやオンラインシステムに行っていた負荷試験を機械学習推論サービスに対しても実施するものです。推論サービスをWebサービスやオンラインシステムと捉えれば、同様の方法論で負荷試験を行うことができます。機械学習の推論サービスは多くの場合、処理速度がCPU依存になることが多いため、スピードや同時リクエスト数が目標を満たさない場合、CPUやサーバ台数の調整を行う必要があります。また、Pythonで推論サービスを構築している場合、Pythonは1プロセス=1スレッドで稼働し、Global interpreter lockの制約を受けるため、リソースを有効活用できないことがあります。その場合、マルチプロセスやwsgi等のライブラリで同時実行数を増やす必要があります。
加えて機械学習の負荷試験時に検討すべきは入力データの種類です。サービスによっては画像や音声、動画、テキストといった容量の大きいデータを入力とする場合があります。本番サービスで1枚の画像サイズや音声サイズがランダムな場合、負荷試験でもサイズの長短をランダムに実行する(または最大サイズを入力する)必要があります。入力データは前処理で調整することになりますが、例えば入力データサイズが大きすぎてメモリに乗り切らず、Out-of-memoryでサーバが停止する可能性もあります。そうした場合は前処理の方法やリクエスト前にクライアントでサイズ制限を追加する必要があります。
その他Webサービスの場合、ロードバランサーやネットワーク、または負荷試験サーバ側にボトルネックが存在する可能性もあります。期待するレスポンススピードや同時アクセス数を満たせない場合、負荷試験を構成する各リソースを鳥瞰することが重要です。
Diagram
Pros
- 推論サーバのレスポンススピードや同時アクセス可能数を計測することで、リソース調整や可用性を定義することができる。
- 本番で障害発生時の事前知識を溜めることができる。
Cons
- 負荷テストのコスト。
- 推論モデルのチューニングは難しい。
Needs consideration
- システムのボトルネックとなる箇所
- 多種多様な入力データを用意すること
- 推論モデル自体が遅い場合、モデルの再開発が必要。
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter6_operation_management/load_test_pattern