Loading test pattern
Usecase
- To measure latency of prediction service.
- To run load test on the prediction service to plan required resource for the production.
Architecture
The response latency and number of simultaneous connection available on prediction server are very important factors to maintain the service availability. Even if you develop a brilliant ML model, taking one minute to respond one request, or one request per server, may probably not work on the production service. Of course it can be worked around with a large scale resource or inference GPU as a platform, though it may not as business.
The loading test pattern will give high load on the ML prediction service, just like it has been done on the general web or online service. Taking the prediction service is one form of the web or online service, you can apply the load test in a same manner. While most of the prediction services tend to be dependent on CPU for its performance, if the service cannot afford to succeed in latency or availability requirement, you have to increase the number of CPU core or server. In addition, if you develop the serving application with Python, you may suspect the service is running on one CPU per process, making inefficient use of the resource. In that case, you may need to consider using multiprocessing, wsgi or asgi to fully use resources.
It is also important to consider a form of input data for the load test. Some predictions may use image, sound, movie or test, which tends to be large sized. If the size of a input image is random in the production environment, it is better to try simulating the randomness of the input data size, with variety of pixel and ratio. Those input data may be managed in the preprocess, and if the input data is so large that cannot be loaded to the RAM, it may cause Out-of-memory error to fail the server. In that case, you need to consider restructuring the preprocess or limit the input size.
There may be a possibility that the bottleneck exists in a load balancer, network, proxy or even the load testing environment. If you cannot achieve your required latency or availability, it is better to go over the resources you are using for the load test.
Diagram
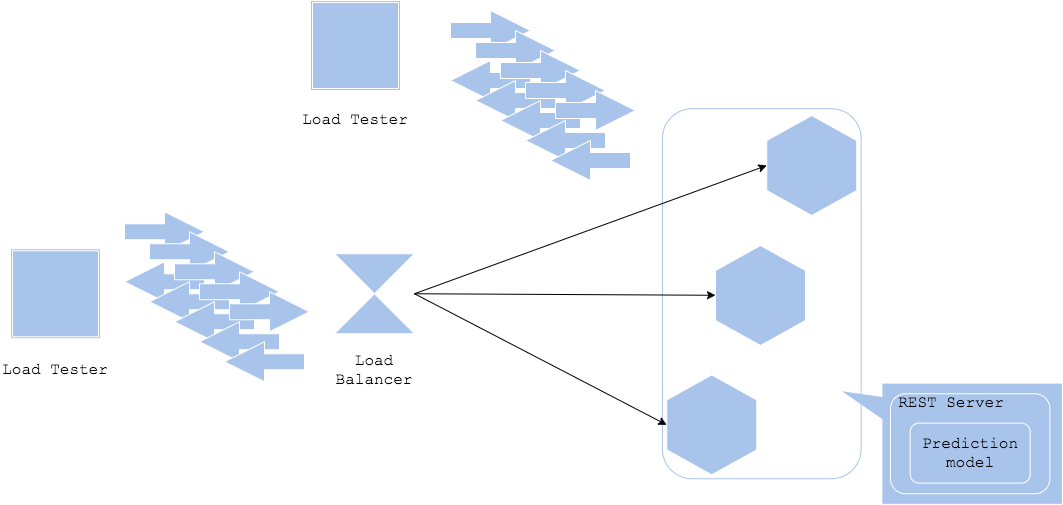
Pros
- You can measure latency as well as the number of simultaneous connections to plan resource for the production environment.
- You may be able to get troubleshooting skills and find bottleneck before going into the production service.
Cons
- Cost.
- Difficult to tune model prediction speed.
Needs consideration
- Bottleneck and work around.
- It is recommended to prepare a variety of dataset.
- If the bottleneck is in model prediction, you may need to redevelop the model.
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter6_operation_management/load_test_pattern