Prediction monitoring pattern
Usecase
- 예측값을 모니터링하고 예측값이 예상과 다르게 나타날 경우 알림을 받고 싶을 때.
- 예측값 트렌드와 통계 관리용.
Architecture
실제 서비스를 운영하기 위해서 로그를 수집하고 인프라와 어플리케이션을 모니터링하는 것은 필수입니다. 특히, 서비스 레벨의 모델을 사용하는 실제 운영 시스템은 예측 결과에 대해서도 모니터링하는 것이 좋습니다.
prediction monitoring pattern에서는 예측을 주로 모니터링합니다. 예측 결과가 의심스러운 경우는 다음과 같이 다양한 케이스가 있습니다.
- 일정 시간 동안 대상에 대한 예측 결과가 없거나, 적어야 할 결과가 너무 많은 경우. 예 : 이상 징후 감지가 너무 많이 탐지된 경우.
- 평소보다 요청이 너무 적거나 너무 많을 때. 예: 100 rps 예상되는 서비스에서 초당 1000건 이상의 요청을 받을 때. 웹서비스에서 오랫동안 요청이 하나도 들어오지 않을 때.
- 동일한 입력값으로 지속적으로 요청이 들어올 때. 예: 특정 입력값으로 계속 재시도가 발생하거나 DDOS 공격.
위와 같은 경우, 서비스 정상화를 위해 사건 분석을 해야 합니다. 이 분석을 위해, 정상과 비정상 상태를 정의하여 모니터링하고 감시할 필요가 있습니다. 요청 빈도에 따라 다르지만, 웹 서비스에서 요청이 적은 것을 이상한 상태라고 판단하기는 어렵습니다. 이러한 판단하기 위해서 장기적으로 로그를 관찰하여 비정상적인 경향을 알아내야 합니다. 이 경우, 로그 저장소나 데이터 웨어하우스에 정기적으로 쿼리하여 트렌드를 모니터링하는 것이 좋습니다. 또는 로그를 시각화하는 대시보드를 사용하는 방법도 있습니다.
모니터링과 알림 설정과 운영은 서비스 레벨이나 중요성에 따라 달라질 수 있습니다. 예를 들어, 큰 비즈니스이거나 사람의 목숨에 관련된 중요한 것이라면, 작은 이상이라도 알림이 가도록 정해야 합니다. 또, 이 경우의 SRE(Site Reliability Engineering)는 24/7으로 지원되어야 합니다. 반대로 중요도가 낮은 서비스라면, 낮에 알림 받는 것만으로도 충분할 수 있습니다. 모니터링 및 알림 구성을 만드는 시스템은 서비스 레벨에 맞게 작업을 정의되어야 합니다. 모든 알림에 대해서가 아니라 서비스 레벨과 중요성에 따라 작업하는 것이 중요합니다.
Diagram
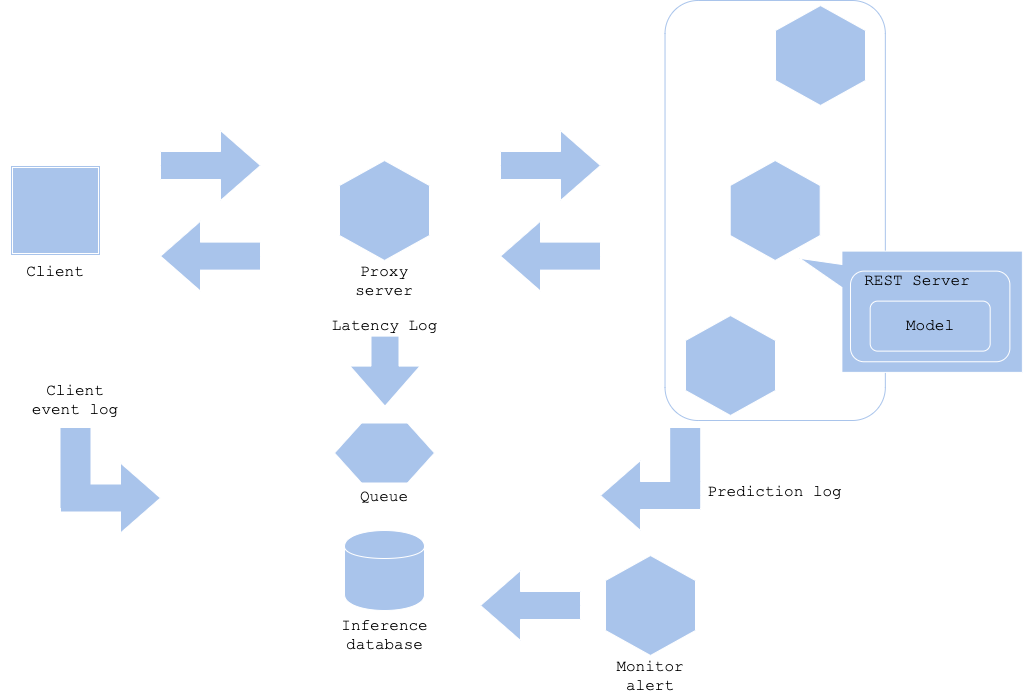
Pros
- 이상 징후를 탐지하고 알림과 함께 장애를 대응할 수 있습니다.
Cons
- 불필요한 알림으로 인해 운용 비용이 증가할 수 있습니다.
Needs consideration
- 서비스 레벨.
- 모니터링 및 알람.
- 레벨에 따른 설정과 운영.
- 대응 방법.
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter5_operations/prediction_monitoring_pattern