Prediction monitoring pattern
Usecase
- When you want to monitor predictions and send alert if the trend is not expected.
- To manage prediction trend and statistics.
Architecture
It is mandatory to take log and monitor infrastructure and application to operate the production service. It may be good to monitor prediction results as well, especially for a production system with service level to the model.
In the prediction monitoring pattern, you will give monitor the inferences. There are multiple cases that the inference result may be suspicious.
- When there is no inference for a target for a certain length of time, or when there is too many of them that should be rare. E.g. Too many anomalies detected on anomaly detection.
- When there is too less, or too many, request compared to usual. E.g. 1000 requests per second happening on 100 rps expected service. E.g. No request for long in web service.
- Continuous requests on a same input data. E.g. Retry occurring continuously for a certain input, or DDOS attack.
In any case, it is necessary to analyze incident to normalize the service. To do so, you need to define the normal and abnormal conditions to monitor and alert. While it depends on the frequency of request, if it is rare to assume anomaly with few prediction in a web service. It is practical to observe from log in longer term to judge incident. In such case, you will monitor log storage or DWH to query regularly to see the change in trend. Or, you may need a dashboard to visualize logs.
Configuration for monitoring and alert, with its operation, depends on service level of the prediction service. If it is critical to a large business or people’s life, then it must make an alert on any small anomaly. In such case, its SRE must be supporting for 24/7. If the service is not so important, then alerting only daytime may be enough. You need to define operation based on service level of the system that makes monitoring and alerting configuration. It is important to make your team to work on the service level and importance of the service, not for all the alerts.
Diagram
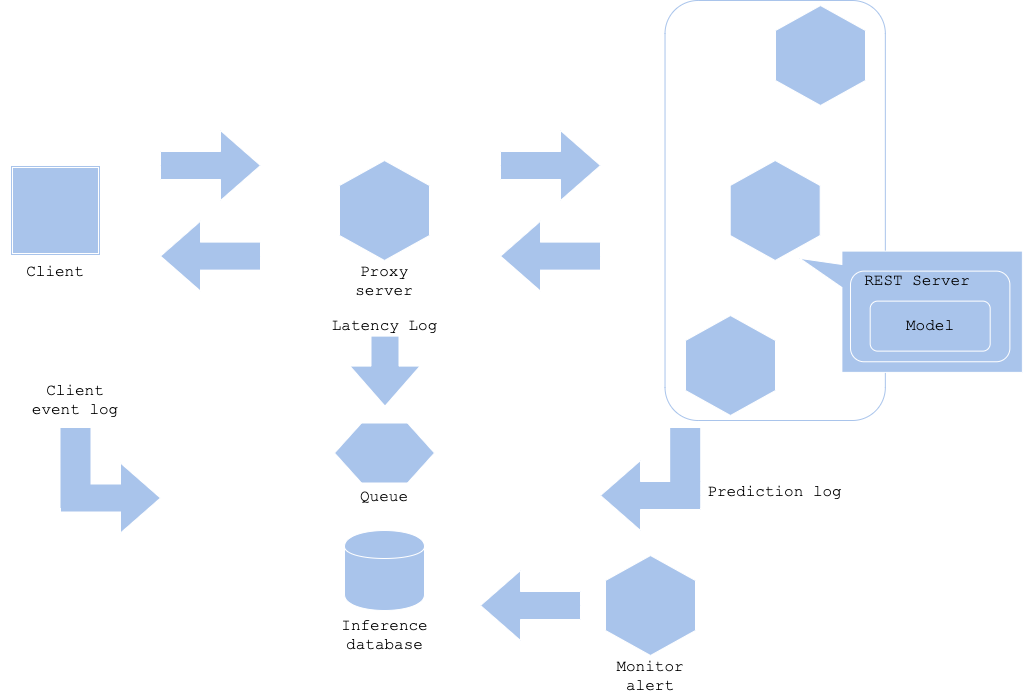
Pros
- Observe anomaly and start fixing an incident with alert.
Cons
- Unnecessary alert may cause increase in operational cost.
Needs consideration
- Service level.
- Monitoring and alert configuration and operation based on the level.
- Playbook.
Sample
https://github.com/shibuiwilliam/ml-system-in-actions/tree/main/chapter5_operations/prediction_monitoring_pattern