[WIP] Data model versioning pattern
Usecase
- When you need to manage data and model versions, which is most of the cases in using machine learning for production.
Architecture
It is difficult of manage version of machine learning model. Just releasing a model into production system requires various components that need version, or naming, management.
- Purpose of using machine learning for the project
- Value (stock price forecast, anomaly detection, face recognition, etc)
- Function (image classification, regression, ranking, etc)
- Release version
- prerelease
- released
- Input and output data and interface
- input datatype and structure
- output datatype and structure
- Code and pipeline
- Training code and pipeline
- Inference code and pipeline
- Environment to run the code and pipeline: library, OS, language, infrastructure and their version
- Hyperparameter
- Depends on algorithm and library
- Data
- Data retrieval
- Splitting of training and testing data (and evaluation data)
In order to make your machine learning reproducible, you need to manage the versions of these components, with reproducibility of the components and model. Since these components are usually managed in differenct repository or DWH, having uniqueness through the warehouses is expected.
This is one of the suggested idea of the versioning.
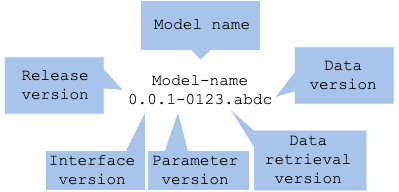
model-name x.y.z-data.split
- Model name (
MODEL-NAME x.y.z-data.split) - Release version (
model-name X.y.z-data.split) - Interface version for input and output (
model-name x.Y.z-data.split) - Logic version including algorithm, library and hyperparameter (
model-name x.y.Z-data.split) - Data retrieval (
model-name x.y.z-DATA.split) - Data store version (
model-name x.y.z-data.SPLIT)
Model name (MODEL-NAME x.y.z-data.split)
You ought to give a name to your model. In order to avoid losing identifying a model in your communication, a name is mandatory. Also, people feel attached to something with a name. Giving a name based on its value or function may make easier to identify, though the naming rule can be defined within your team.
Release version (model-name X.y.z-data.split)
There are two conditions for a model: prerelease and released. For prereleased model, you give 0 to X and for released, 1 or higher.
Interface version for input and output (model-name x.Y.z-data.split)
A machine learning model gives a prediction to your input data. It may differ with your usecase and algorithm, but it is always common on providing an input and getting a prediction. Once its in-out structure changes, you have to change external interface, so it is recommended to manage the interface version to identify with external system. Those interfaces, as well as their datatype and structure, are managed in a code repository, such as Git. It may be good to use Swagger or Protocol Buffer to publicize your API definition externally.
In the interface versioning, you have to only manage the version for your in-out interface, and not internal algorithm, library and model evaluation. Its algorithm and library are managed in logic version, and the model evaluation in model version in a model repository. For the versioning rule, you may start with 0 and increment with update to keep uniqueness of the interface.
Logic version including algorithm, library and hyperparameter (model-name x.y.Z-data.split)
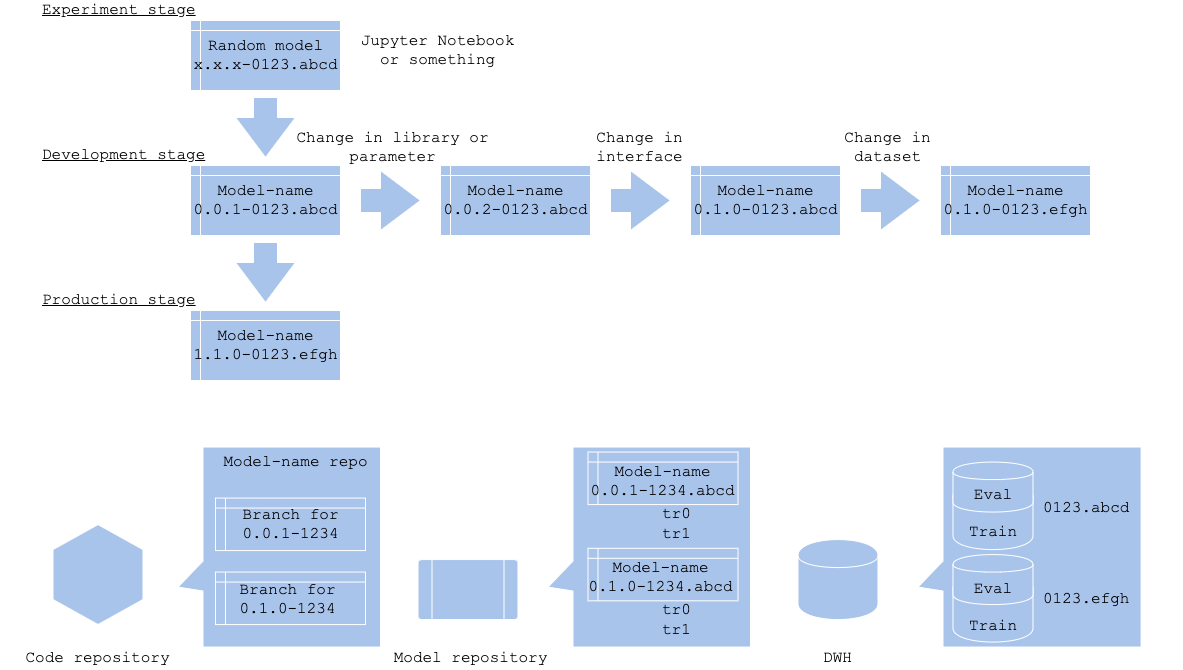
There are plenty of preprocess and prediction algorithms in machine learning training and prediction, including optimization and loss fuction. Usage and tunable parameters vary depending on its language and library. The logic versioning controls preprocess, algorithm, library, and parameter that do not change interface. These changes will be managed in a code repository as a branch. It is not necessary to manage every version at experimental and development stage, or you will lose control of versioning if you do. Suggested to start version management once the model is ready for your team review.
There may be a chance that model’s evaluation or loss may differ without changing its algorithm and paramater. In that case, you may store the evaluation along with a training version in your model repository. Since it is difficult to control the variation, it is better to manage as a set of training and evaluation instead of its model version.
Data retrieval (model-name x.y.z-DATA.split) and Release version (model-name X.y.z-data.split)
Data will be stored in some kind of DWH. Since dataset to be used in a training will be defined in the training phase, it is recommended to store the splitted data, training and testing, and maybe evaluation, separately. An important point of data versioning is to enable to retrieve the same data, without mixing up training and testing, to avoid abnormal evaluation. It is better to manage both data retrieval method as well as splitted dataset, to be able to retrieve the dataset again. At same time, it is recommended to record the dataset in specific DWH’s (record in a table in database for structured data, and zip in an object storage or file storage for unstructured data).
It is necessary to manage versions for data retrieval method (model-name x.y.z-DATA.split) and splitted dataset (model-name x.y.z-data.SPLIT). Each may be better to use string versioning rather than incremental integer, or may use timestamp. The data retrieval method will be managed as query or data pipeline definition in a code repository, and dataset in DWH.
The interface, logic, and data retrieval are written in programming code, so they will be recorded in a code repository. If you manage them in branch, then those will naturally be controlled in the code repository’s workflow, such as gitflow or github flow.
It is good to manage the model file and its evaluation in a model repository. A problem is that there are many model repository like software or service, though there is no standardized one, that you may need to define your workflow for the versioning.
The dataset are stored in your DWH or storage. It is good to give a name to the table and bucket corresponding to the version.
Diagram
Versioning
Version control in each stage
Pros
- Able to manage model versions.
- Manage components to make model creation reproducible.
- Retraining and update management.
Cons
- Code, model and data are managed in multiple environments.
Needs consideration
- Selecting repository and DWH.
- How to use them, including workflow.